
Teapot AI Models
Collection
2 items • Updated
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
Website | Try out our Demo | Join the discussion on Discord
TinyTeapot is a lightweight (~77M parameter) grounded language model optimized for low-latency, hallucination-resistant question answering and RAG workflows. Building on our prior work, TeapotLLM, TinyTeapot delivers strong context-faithful performance while being ~10× faster on CPU, making it ideal for real-time, on-device, and cost-efficient deployments across CPUs, mobile devices, and other resource-constrained environments.
TinyTeapot is distilled from our previous model, TeapotLLM, and trained on grounded datasets including SynthQA, a context-focused QnA and extraction benchmark, and TeapotChat for instruction-following and grounded dialogue. This distillation transfers TeapotLLM’s refusal behavior, structured extraction patterns, and context-only answering into a significantly smaller, edge-efficient model.
Through distillation from TeapotLLM and training on SynthQA, TinyTeapot learns to refuse questions when the answer is not present in the context, improving reliability compared to similarly sized models in RAG and document QA pipelines.
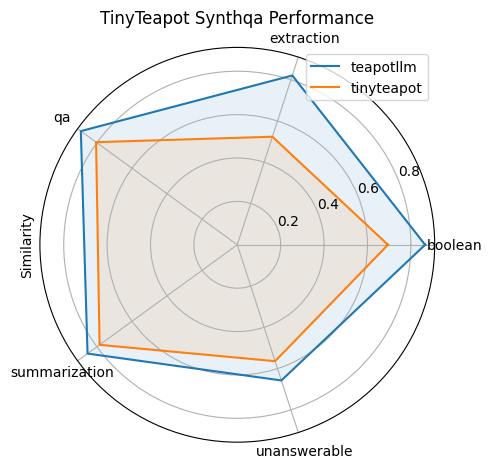
TinyTeapot is evaluated primarily against its teacher model (TeapotLLM) on SynthQA-style grounded tasks, with additional comparisons to larger instruction-tuned models such as LLaMA and Qwen to contextualize efficiency vs quality tradeoffs.
The chart below shows task-level similarity across boolean reasoning, QA, extraction, summarization, and unanswerable queries. While smaller (~77M vs ~800M+), TinyTeapot retains strong grounded behavior due to distillation from TeapotLLM and training on SynthQA and TeapotChat.
TinyTeapot is designed for real-time and edge deployments where latency is critical. Benchmarks on Google Colab (100 runs) show that TinyTeapot delivers competitive grounded similarity while being dramatically faster than larger models.
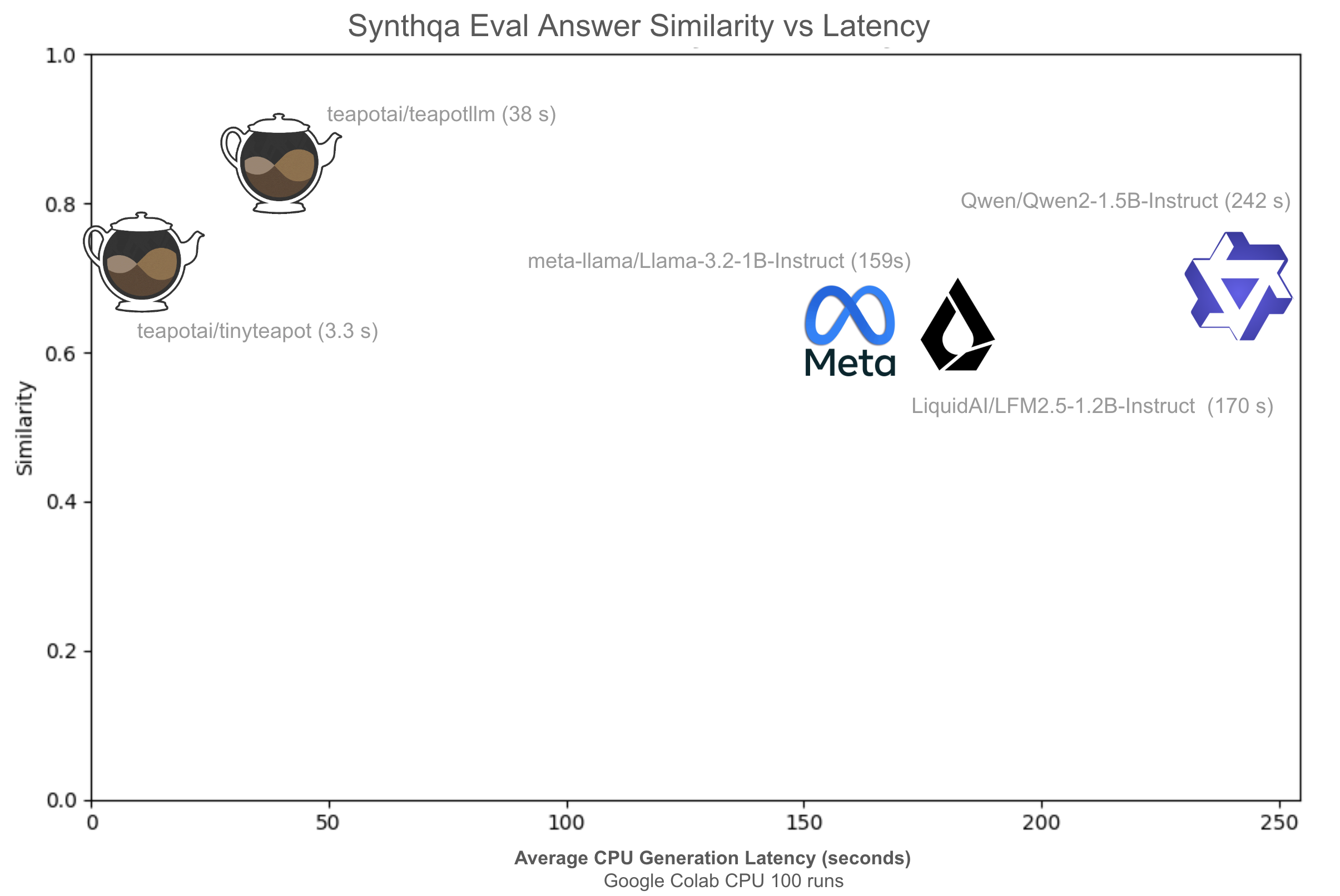
Key observations:
These results position TinyTeapot as a high-efficiency distilled model that preserves TeapotLLM’s grounded reasoning while enabling low-cost, low-latency deployment.
TinyTeapot can be used directly with Hugging Face Transformers or with our python library teapotai and follows a text-to-text format. It performs best when given explicit grounding context and the pre-trained system prompt.
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
MODEL_NAME = "teapotai/tinyteapot"
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForSeq2SeqLM.from_pretrained(MODEL_NAME)
# Context
context = (
"The Eiffel Tower is a wrought iron lattice tower in Paris, France. "
"It was designed by Gustave Eiffel and completed in 1889. "
"It stands at a height of 330 meters and is one of the most recognizable "
"structures in the world."
)
# System prompt
system_prompt = (
"You are Teapot, an open-source AI assistant optimized for low-end devices, "
"providing short, accurate responses without hallucinating while excelling at "
"information extraction and text summarization. "
"If the context does not answer the question, reply exactly: "
"'I am sorry but I don't have any information on that'."
)
def ask(question: str):
prompt = f"{context}\n{system_prompt}\n{question}\n"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(
**inputs,
do_sample=False
)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"{question}")
print(f"{answer}\n")
# Test 1: Grounded question (should use context)
ask("How tall is the Eiffel Tower") # => 330 meters
# Test 2: Out-of-context question (tests hallucination resistance)
ask("How tall is the Death Star") # => Sorry, I don't have any information on the Death Star.
TinyTeapot performs best when paired with retrieval or structured context inputs rather than open-ended chat.
TinyTeapot is optimized for grounded QnA, RAG, and extraction. It is not intended for open-ended chat, creative writing, or deep multi-step reasoning. Due to its small size (~77M parameters), performance is highly dependent on the quality and relevance of the provided context and may be more prone to hallucinations.
We hope you find TinyTeapot useful and are continuously improving the TeapotAI ecosystem. Please reach out on our Discord for technical help, feedback, or feature requests. We look forward to seeing what the community builds!
MIT License ⠀
Base model
google/flan-t5-small